from siuba.data import cars
from siuba import _, filter
filter(cars, _.mpg == _.mpg.max())| cyl | mpg | hp | |
|---|---|---|---|
| 19 | 4 | 33.9 | 65 |
siuba (小巴) is an analysis framework that makes data science faster. It provides a simple, consistent interface that handles messy, real-life data.
Use the same code to work directly with a pandas DataFrame, or execute SQL queries against a database—such as postgresql, duckdb or snowflake.
Everybody has to start somewhere. Bring your questions, bring your hot takes, bring the excel spreadsheets your boss emailed you.
from siuba.data import cars
from siuba import _, filter
filter(cars, _.mpg == _.mpg.max())| cyl | mpg | hp | |
|---|---|---|---|
| 19 | 4 | 33.9 | 65 |
from siuba.data import cars
from siuba import _, arrange
arrange(cars, _.mpg)| cyl | mpg | hp | |
|---|---|---|---|
| 14 | 8 | 10.4 | 205 |
| 15 | 8 | 10.4 | 215 |
| ... | ... | ... | ... |
| 17 | 4 | 32.4 | 66 |
| 19 | 4 | 33.9 | 65 |
32 rows × 3 columns
from siuba.data import cars
from siuba import _, select
select(cars, ~_.hp)| cyl | mpg | |
|---|---|---|
| 0 | 6 | 21.0 |
| 1 | 6 | 21.0 |
| ... | ... | ... |
| 30 | 8 | 15.0 |
| 31 | 4 | 21.4 |
32 rows × 2 columns
from siuba.data import cars
from siuba import _, mutate
mutate(cars, demeaned = _.hp - _.hp.mean())| cyl | mpg | hp | demeaned | |
|---|---|---|---|---|
| 0 | 6 | 21.0 | 110 | -36.6875 |
| 1 | 6 | 21.0 | 110 | -36.6875 |
| ... | ... | ... | ... | ... |
| 30 | 8 | 15.0 | 335 | 188.3125 |
| 31 | 4 | 21.4 | 109 | -37.6875 |
32 rows × 4 columns
from siuba.data import cars
from siuba import _, group_by, summarize
summarize(cars, hp_per_cyl = (_.hp / _.cyl).mean())| hp_per_cyl | |
|---|---|
| 0 | 23.001302 |
group_by()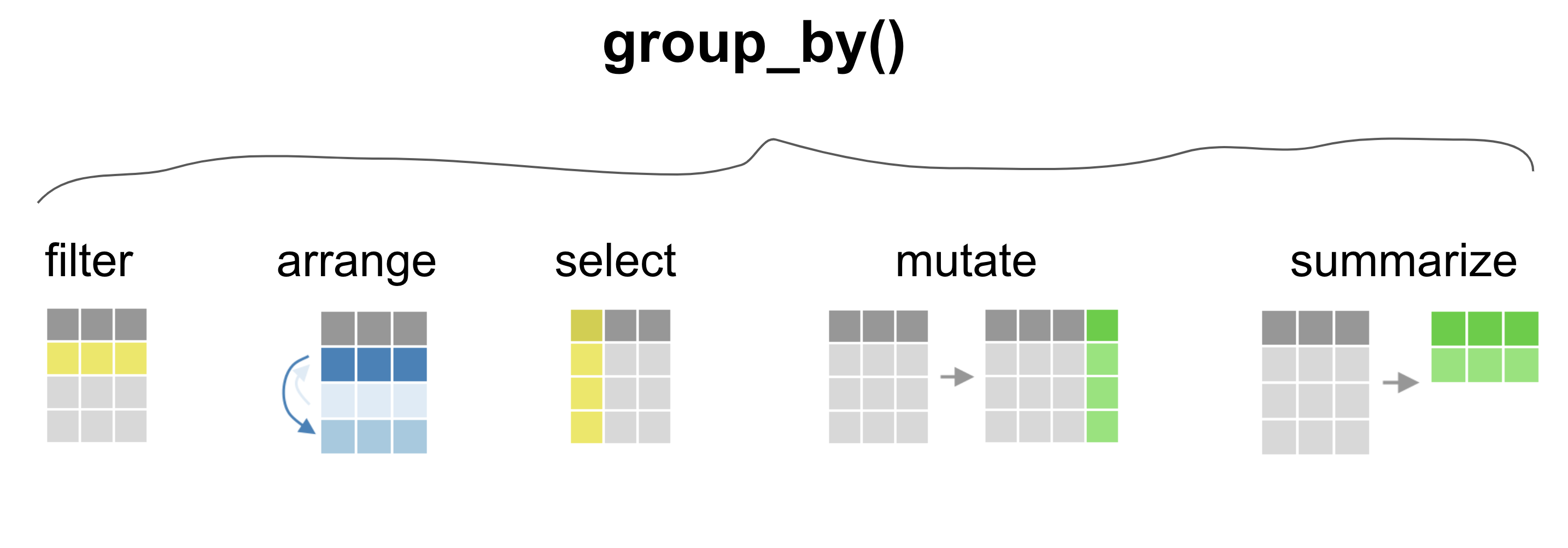
>>) puts it all togetherfrom siuba.data import mtcars
from siuba import _, group_by, filter
(mtcars
>> group_by(_.cyl)
>> filter(_.hp == _.hp.max())
)(grouped data frame)
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 27 | 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.9 | 1 | 1 | 5 | 2 |
| 29 | 19.7 | 6 | 145.0 | 175 | 3.62 | 2.770 | 15.5 | 0 | 1 | 5 | 6 |
| 30 | 15.0 | 8 | 301.0 | 335 | 3.54 | 3.570 | 14.6 | 0 | 1 | 5 | 8 |
from siuba import _, tbl, group_by, filter
from siuba.data import cars
# setup ----
# analysis ----
(cars
>> group_by(_.cyl)
>> filter(_.mpg < _.mpg.mean())
)(grouped data frame)
| cyl | mpg | hp | |
|---|---|---|---|
| 2 | 4 | 22.8 | 93 |
| 5 | 6 | 18.1 | 105 |
| ... | ... | ... | ... |
| 30 | 8 | 15.0 | 335 |
| 31 | 4 | 21.4 | 109 |
16 rows × 3 columns
from siuba import _, tbl, group_by, filter
from siuba.data import cars
# setup ----
from sqlalchemy import create_engine
engine = create_engine("duckdb:///:memory:")
# analysis ----
(tbl(engine, "cars", cars)
>> group_by(_.cyl)
>> filter(_.mpg < _.mpg.mean())
)# Source: lazy query # DB Conn: Engine(duckdb:///:memory:) # Preview:
| cyl | mpg | hp | |
|---|---|---|---|
| 0 | 4 | 22.8 | 93 |
| 1 | 4 | 24.4 | 62 |
| 2 | 4 | 22.8 | 95 |
| 3 | 4 | 21.5 | 97 |
| 4 | 4 | 26.0 | 91 |
# .. may have more rows
from siuba import _, tbl, group_by, filter
from siuba.data import cars
# setup ----
from sqlalchemy import create_engine
engine = create_engine("sqlite:///:memory:")
cars.to_sql("cars", engine, index=False)
# analysis ----
(tbl(engine, "cars")
>> group_by(_.cyl)
>> filter(_.mpg < _.mpg.mean())
)# Source: lazy query # DB Conn: Engine(sqlite:///:memory:) # Preview:
| cyl | mpg | hp | |
|---|---|---|---|
| 0 | 4 | 22.8 | 93 |
| 1 | 4 | 24.4 | 62 |
| 2 | 4 | 22.8 | 95 |
| 3 | 4 | 21.5 | 97 |
| 4 | 4 | 26.0 | 91 |
# .. may have more rows
See the examples page.
Visit siuba on github, or open an issue with a bug or feature request.